作者:Devansh 翻译:陈之炎 校对:ZRX
最近偶然发现了一个很棒的 YouTube 视频,“ Pinterest 6 名工程师让用户扩展到1100万 ”,以及另一篇文章,“ Pinterest 的扩展历程 —— 从 0 到每月数十亿页面浏览量,仅用了两年 ”。我认为二者都是学习系统设计的极好资源( 强烈推荐大家阅读 )。本文将对学习这些资源时发现的最重要内容做出总结。
Pinterest 演进路线图
Pinterest 的扩展历程可以分为四个不同的阶段:
自我发现阶段:这一阶段以快速原型制作和不断演变的产品需求为特征,由一个小的项目团队管理。
做实验阶段:指数级的用户增长要求快速扩张,虽然采用了许多技术但还是一个复杂、脆弱的系统。
As a result you end up with a very complicated picture.
- Amazon Ec2+ S3 + CloudFront
- 2NGinX, 16 Web Engines + 2 API Engines
- 5 Functionally sharded MysoL DB+ 9 read slaves
- 4 Cassandra Nodes
- 15 Mlembase Nodes I3 separate clusters!
- 8 mMlemcache Nodes
- l0 Redis Nodes
- 3 Task Routers + 4 Task Processors
- 4 Elastic Search Nodes
- 3 Mongo clusters
- 3 Engineers
5 major database technologies for just their data alone.
Growing so fast that Mlysa was hot and all the other technologies were being pushed to the limits.
When you push something to the limit all these technologies fail in their own special Way.
Started dropping technologies and asked themselves what they really wanted to be. Did a massive rearchitecture of everything.
成熟阶段:这一阶段涉及有意识对架构进行简化,专注于像MySQL、Memcache和Redis等成熟、可扩展的技术。Pinterest没有增加技术栈,而是将资金投入到运作良好的领域。
After everything was rearchitected the system now looks like!
- AmazonEC2 + S3 + Akamai, ELB
- 90 Web Engines + 50 API Engines
- 66 MySQL DBs (mi.xlarge)+ 1slave each
- 59 Redis Instances
- 51 Memcache Instances
- 1 Redis Task Manager + 25 Task Processors
- Sharded Solr
- 6 Engineers
Now on sharded MySQL,Redis, Memcache, and Solr. That’s it. The advantage is it’s really simple and mature technologies.
Web traffic keeps going up at the same velocity and iPhone traffic starts ramping up.
回报阶段:有了正确的架构,Pinterest通过水平扩展继续其增长轨迹,验证了其选择的正确性。
The numbers now looks like:
- Amazon EC2 + S3 + Edge Cast.Akamai, Leyel 3
- 180 Web Engines + 240 API Engines
- 88 MySQL DBs (cc2.8xlarge) + 1 slave each
- 110 Redis Instances
- 200 mlemcache Instances
- 4 Redis Task Manager + 80 Task Processors
- Sharded Soir
- 40 Engineers (and growing)
Notice that the architecture is doing the right thing. Growth is by adding more of the
Same stuff. You want to be able to scale by throwing money at the problem. You want to
just be able to throw more boxes at the problem as you need them.
Now moving to SSDs.
接下来看看经过残酷的重新架构清洗后留下来的技术。
核心技术:可扩展的构建块
Pinterest 优先考虑可靠、被广泛理解并且可以轻松扩展以适应用户数不断增长的基础技术。让我们深入了解这些技术:
- MySQL:强大且成熟的关系型数据库管理系统,以其稳定性和广泛的用户社区而闻名。它易于维护,故障排除简单,并能够雇佣到熟悉这项技术的工程师。最重要的是,它是我最喜欢的f词:免费。
- Memcache:一个简单、高性能的系统,用于在内存中缓存频繁访问的数据。Memcache 的简单性和可靠性使其成为数据库读取的理想选择,它也是免费的。
- Redis:多功能的数据存储,能够处理各种数据结构,并在持久性和备份方面具备灵活性。Pinterest 根据数据敏感性定制持久性策略,正如你猜到的,这也是免费的。
- Solr:选择它是因为可以快速使用。此外,团队“ 尝试了 Elasticsearch,但它在规模上受限,在处理大量小文档和大量查询时会遇到麻烦。”
集群与分片:如何扩展数据库
随着数据量的激增,Pinterest 面临一个关键选择:如何分布式处理数据库负载?出现了两种主要方法,每种都有其各自优缺点。
了解集群
“ 数据库集群是将多个单一数据库实例或服务器连接到系统的过程。在大多数常见的数据库集群中,通常由一个主服务器管理多个数据库实例。”
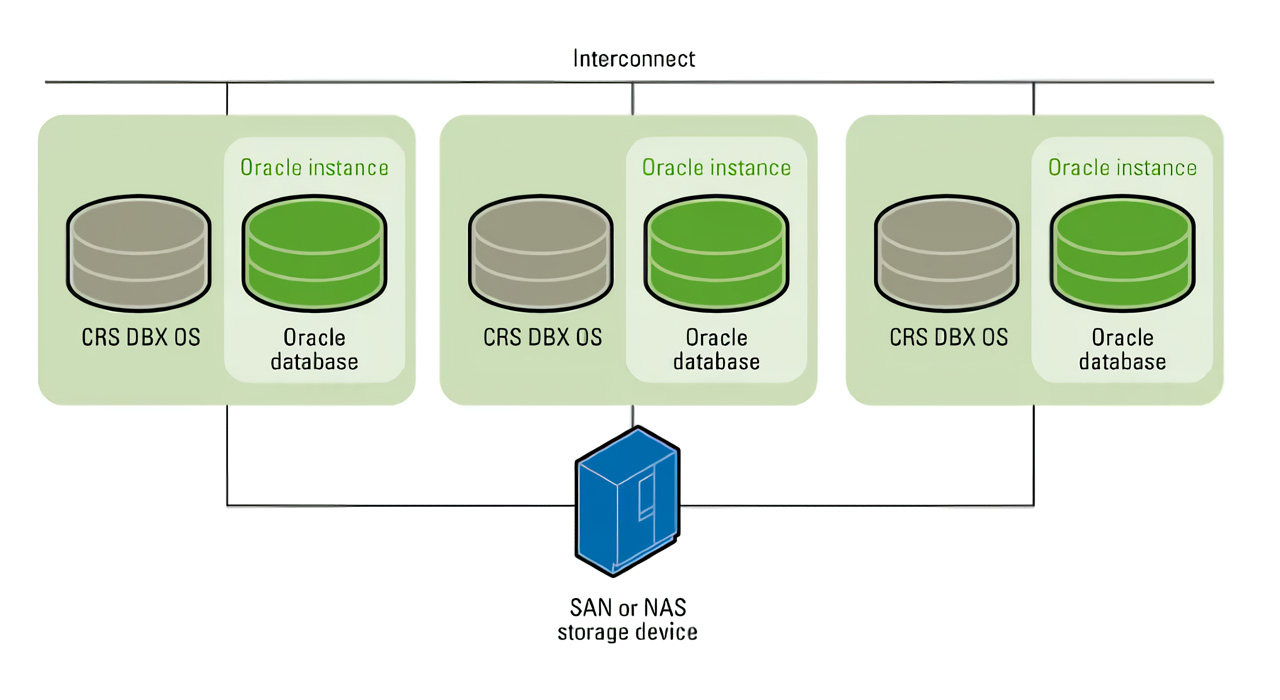
集群的动作:
- 1、来了一个新的数据片段。
- 2、集群算法确定此数据的最佳节点。
- 3、数据在多个节点之间复制以实现冗余。
- 4、如果一个节点失败,其他节点接管,确保数据可用性。
优点:
- 1、自动扩展:自动添加新节点实现容量扩展。
- 2、易于设置:集群技术管理数据放置和分发,简化了初始设置。
- 3、地理数据分布:集群可以分布在不同的地理位置,提高数据本地性和对数据中心中断的弹性。
- 4、高可用性:数据复制和自动故障转移确保即使单个节点失败也能持续运行。
- 5、负载均衡:工作负载分布在节点之间,防止单个节点变得不堪重负。
缺点:
- 复杂性:集群引入了节点之间的复杂交互,使故障排除和维护更加困难。
- 成熟度:Pinterest 做出决定时,集群技术的成熟度有限,经验丰富的工程师和社区支持较少。
- 升级挑战:由于需要在多个节点上进行协调变更,升级集群会变得更加复杂。
- 单点故障:负责协调动作的集群管理算法可能成为单点故障,算法问题会影响到整个集群。
了解分片
想象一下,是否能将数据分成更小的块,并将每个块放在一个单独的、独立服务器上,这就是分片。与依赖自动协调不同,应用程序确定数据的位置并实施路由查询。
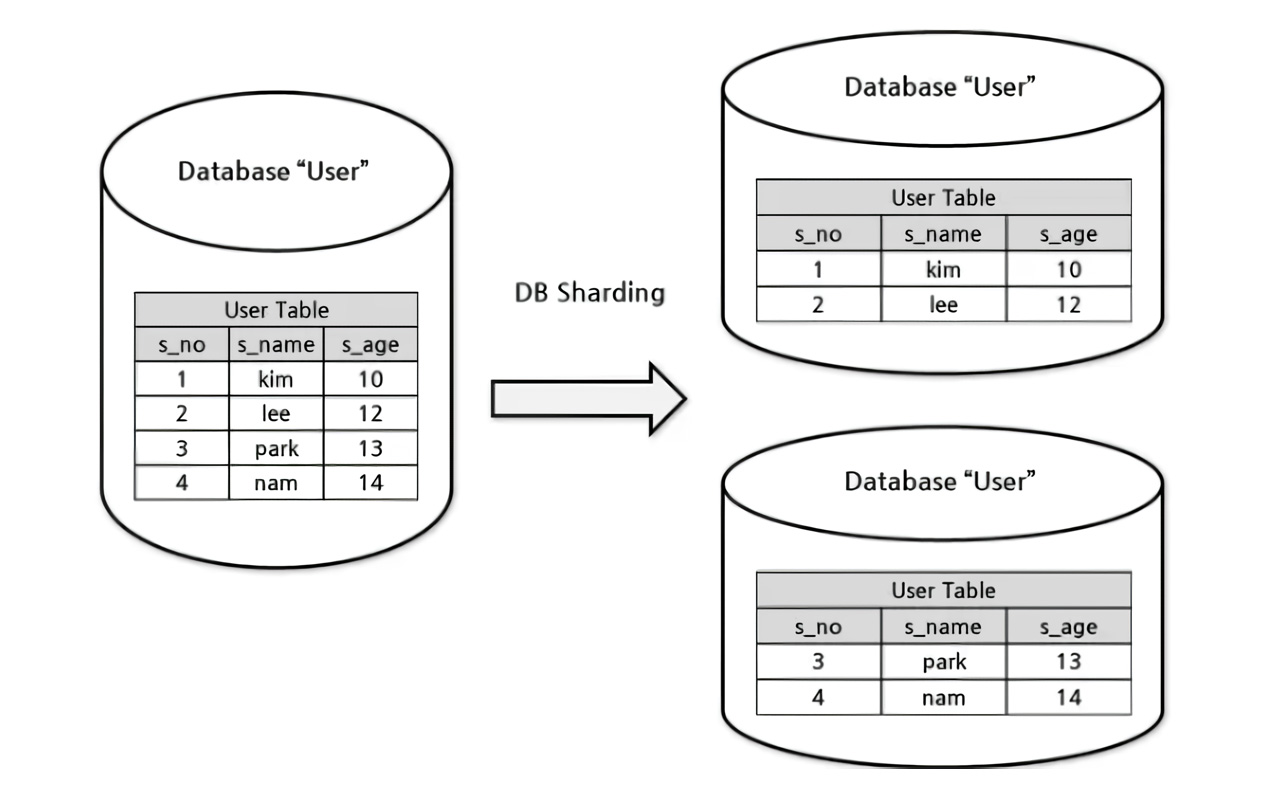
分片的动作:
- 1、根据特定标准( 例如,用户 ID )对数据进行分区。
- 2、不同分区( 分片 )位于专用服务器上。
- 3、应用程序确定给定查询的正确分片。
- 4、可以复制分片内的数据以实现高可用性。
优点:
- 架构简单:分片消除了复杂的节点间通信和自动数据分发,使系统更简单,易于理解和管理。
- 独立扩展:各个分片可以独立扩展,提供更细粒度的资源分配控制。
- 清晰的数据所有权:每个分片都有明确的责任,负责特定数据子集,消除了在集群中可能出现的所有权模糊。
- 简化算法:数据放置的逻辑比集群管理算法简单得多,减少了发生灾难性故障的可能。
缺点:
- 1、没有数据库级连接:由于数据分布在多个分片上,跨不同分片执行连接变得具有挑战性。通常需要对数据进行规范化或在应用程序层执行连接。
- 2、没有数据库级事务:无法跨越多个分片,需要应用程序级逻辑来维护数据的一致性和完整性。
- 3、应用程序复杂性增加:应用程序必须处理分片路由和管理跨分片的数据一致性,增加了开发过程的复杂性。
- 4、更复杂的模式更改:需要对所有单独的分片应用更改之后才能修改数据库模式。
- 5、报告复杂性:需要从每个分片检索数据并手动聚合结果之后才能生成跨多个分片报告。
为什么 Pinterest 选择了分片
Pinterest 选择分片而没有选择集群,因为分片相对简单,从在“做实验阶段”采用集群的负面经验来看,集群管理面临以下问题:
- 1、集群管理问题:集群管理算法中的错误导致多次中断,并且难以排除故障。
- 2、数据重新平衡问题:自动重新平衡会导致性能瓶颈和数据一致性问题。
- 3、数据所有权混淆:出现了次要节点错误地承担主要角色的情况,导致数据丢失。“ 在一个案例中,引入一个新的次要节点。大约有 80% 的概率,次要节点说它是主节点,主节点变成了次要节点,为此丢失了 20% 的数据。丢失 20% 的数据比丢失全部数据更糟糕,因为不知道丢失了什么内容。”
分片提供了一种更可预测和可管理的方法,为此应用程序层面为了增加控制和简单性而牺牲某些数据库级的特性,如连接和事务。
迁移至分片架构
向分片架构迁移并非一蹴而就,Pinterest为此采取了分阶段的方法,在功能冻结期间执行迁移,将用户受影响降到最低:
- 消除连接:移除所有MySQL连接,需要将数据解规一化,通过增加对缓存的依赖以确保性能。缓存弥补了丢失连接对性能的影响,解决需要查询多个分片的需求。
- 基于ID的分片:这个阶段涉及基于64位ID的分片。此ID嵌入了分片位置,消除了单独查找表的需要,并简化了数据路由。“对于某个特定用户来说全部数据(pins,boards等)都位于同一个分片上,由此带来巨大的优势,例如,不需要多个跨分片查询便能很快渲染某个用户的配置文件”。
分阶段逐步实施迁移方法,并在每个阶段进行验证。
分片的代价:缺点和解决方案
虽然分片提供了一种更可管理的方法,但它同时带来了 Pinterest 必须解决的挑战:
- 迁移脚本编写:将大量数据迁移到分片架构比预期更耗时,需要强大的脚本工具和流程。
- 应用程序逻辑:缺乏数据库级连接和事务,这要求开发人员在应用程序层实现维护数据的一致性和完整性逻辑。
- 架构修改:修改数据库架构需要仔细规划,并在所有分片上应用更改。
- 报告障碍:生成跨多个分片报告时需要额外的步骤来聚合各分片的结果。
从 Pinterest 中学到的智慧和收获:
Pinterest 的扩展旅程为构建扩展系统的人们提供了宝贵的经验:
- 1、简单是关键:选择简单、被广泛理解的技术简化故障排除,降低不可预见问题的风险。
- 2、优先考虑可扩展性:愿意为可扩展性牺牲某些数据库特性,尤其是在快速增长的环境中。
- 3、为水平增长设计:选择一个允许随着用户量的扩展能添加更多资源的架构。
通过拥抱简单性,强调可扩展性,并从经验中学习,Pinterest 成功地应对了爆炸性用户增长带来的挑战。他们的故事为构建和扩展高性能、分布式系统提供了宝贵的资源。
相关文章

