适用于语音识别的工具
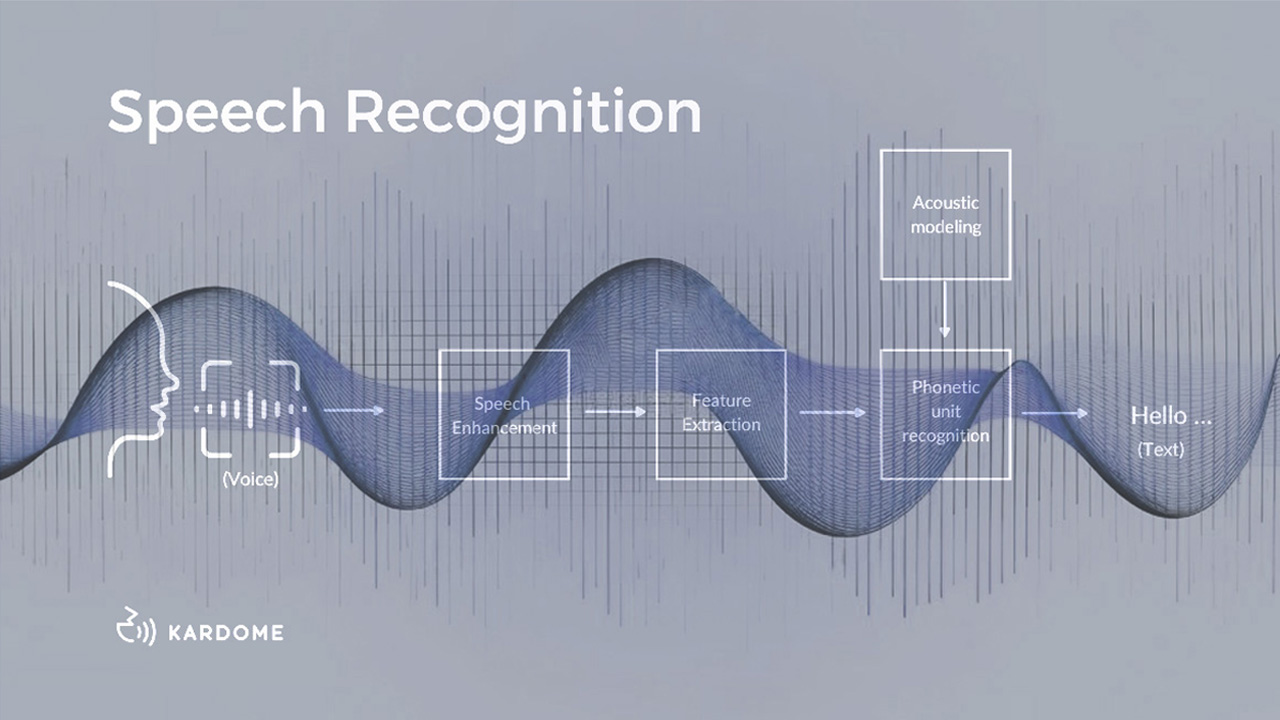


Kaldi 是目前使用广泛的开发语音识别应用的框架。
该语音识别工具包使用了 C++编写,研究开发人员利用 Kaldi 可以训练出语音识别神经网路模型,但如果需要将训练得到的模型部署到移动端设备上,通常需要大量的移植开发工作。
GitHub 地址:https://github.com/kaldi-asr/kaldi


DeepSpeech 是一个开源语音转文本引擎,使用基于百度深度语音研究论文的机器学习技术训练的模型。其中,该项目运用到了 Google 的 TensorFlow 来简化实施过程。
GitHub 地址:https://github.com/mozilla/DeepSpeech


这是由 Facebook 人工智能研究院发布的首个全卷积自动语音识别工具包,它是一个简单高效的端到端自动语音识别( ASR )系统。
wav2letter 的核心设计基于三个关键原则,包括:实现在包含成千上万小时语音数据集上的高效模型训练;简单可扩展模型,可以接入新的网络架构、损失函数以及其他语音识别系统中的核心操作;以及平滑语音识别模型从研究到生产部署的过渡。
适用于计算机视觉的工具


YOLO 是当前深度学习领域解决图像检测问题最先进的实时系统。在检测过程中,YOLO 首先将图像划分为规定的边界框,然后对所有边界框并行运行识别算法,来确定物体所属的类别。确定类别之后,YOLO 再智能地合并这些边界框,在物体周围形成最优边界框。
这些步骤全部并行进行,因此 YOLO 能够实现实时运行,并且每秒处理多达 40 张图像。据官网显示,在 Pascal Titan X 上,它以 30 FPS 的速度处理图像,并且在 COCO 测试开发中的 mAP 为 57.9%。
GitHub 地址:https://github.com/allanzelener/YAD2K


OpenCV 是英特尔开源的跨平台计算机视觉库( https://opencv.org ),被称为 CV 领域开发者与研究者的必备工具包。
这是一套包含从图像预处理到预训练模型调用等大量视觉 API 的库,并可以处理图像识别、目标检测、图像分割和行人再识别等主流视觉任务。其最显著的特点是它提供了整套流程的工具,因此开发者无需了解各个模型的原理就能用 API 构建视觉任务。它具备 C++、Python 和 Java 接口,支持 Windows、Linux、Mac OS、iOS 和 Android 系统。
GitHub 地址:https://github.com/opencv/opencv


Detectron2 则是 PyTorch 1.3 中一重大新工具,它源于 maskrcnn 基准测试,也是对先前版本 detectron 的一次彻底重写。
Detectron2 通过全新的模块化设计,变得更灵活且易于扩展,它能够在单个或多个 GPU 服务器上提供更快速的训练速度,包含了更大的灵活性与扩展性,并增强了可维护性和可伸缩性,以支持在生产中的用例。


OpenPose 人体姿态识别项目是美国卡耐基梅隆大学( CMU )基于卷积神经网络和监督学习并以 caffe 为框架开发的开源库。
它可以实现人体动作、面部表情、手指运动等姿态估计。适用于单人和多人,具有极好的鲁棒性。是世界上首个基于深度学习的实时多人二维姿态估计应用,很多人体姿态估计实例都是基于它实现,如动作采集、3D 试衣、绘画辅助等。
GitHub 地址:https://github.com/CMU-Perceptual-Computing-Lab/openpose


FaceNet 采用了深度卷积神经网络( CNN )学习将图像映射到欧式空间,也被称为通用人脸识别系统。
该系统可从人脸中提取高质量的特征,称为人脸嵌入( face embeddings ),可用于训练人脸识别系统,从而实现对人脸的验证。它在 LFW 数据集上测试的准确率达到了99.63%,在 YouTube Faces DB 数据集上准确率为 95.12%。
GitHub 地址:https://github.com/davidsandberg/facenet
相关文章

